I am a Research Scientist at Adobe Research, where I lead multiple research-to-production projects in generative image and video editing. My work spans unified editing frameworks (EditVerse, ICLR'26 Oral), generative video propagation (GenProp, Adobe MAX Sneak 2025), and physically-grounded shadow understanding (MetaShadow, shipped in Lightroom & Photoshop). I am equally driven by fundamental questions — how should we train visual generative models from scratch, and can editing and generation be unified into a single paradigm? These threads are converging on my broader vision: building world-aware visual foundation models that inherently understand the physical constraints of our world. I received my Ph.D. from The Chinese University of Hong Kong, advised by Prof. Chi-Wing Fu. When I'm not pushing pixels through neural networks, I'm exposing them on film — a slower way of seeing that keeps me close to the beauty I'm trying to teach machines to understand.
Publications
Click a paper to see details
Selected Works

EditVerse: Unifying Image and Video Editing and Generation with In-Context Learning
Xuan Ju, Tianyu Wang, Yuqian Zhou, He Zhang, Qing Liu, Nanxuan Zhao, Zhifei Zhang, Yijun Li, Yuanhao Cai, Shaoteng Liu, Daniil Pakhomov, Zhe Lin, Soo Ye Kim†, Qiang Xu†
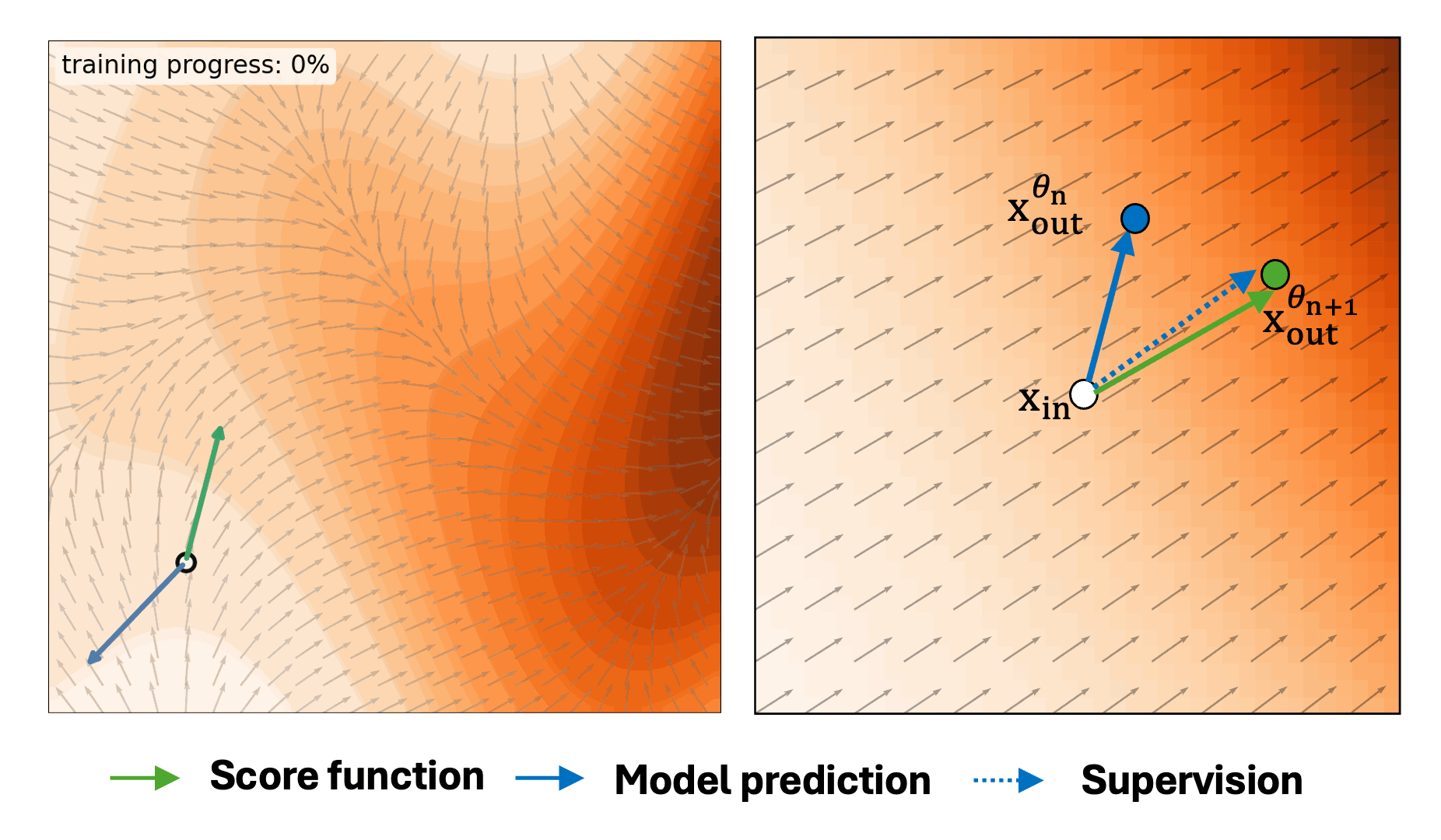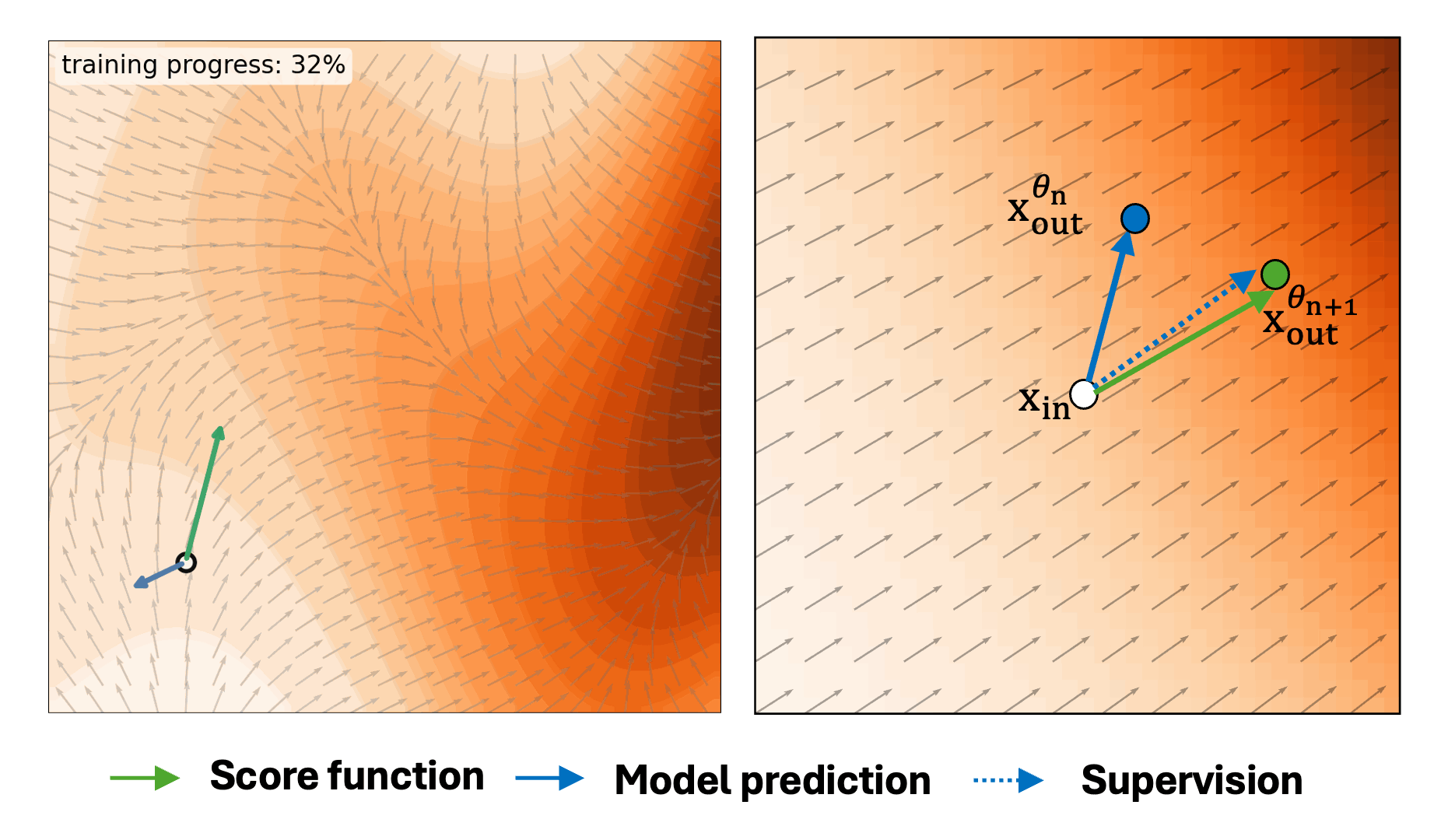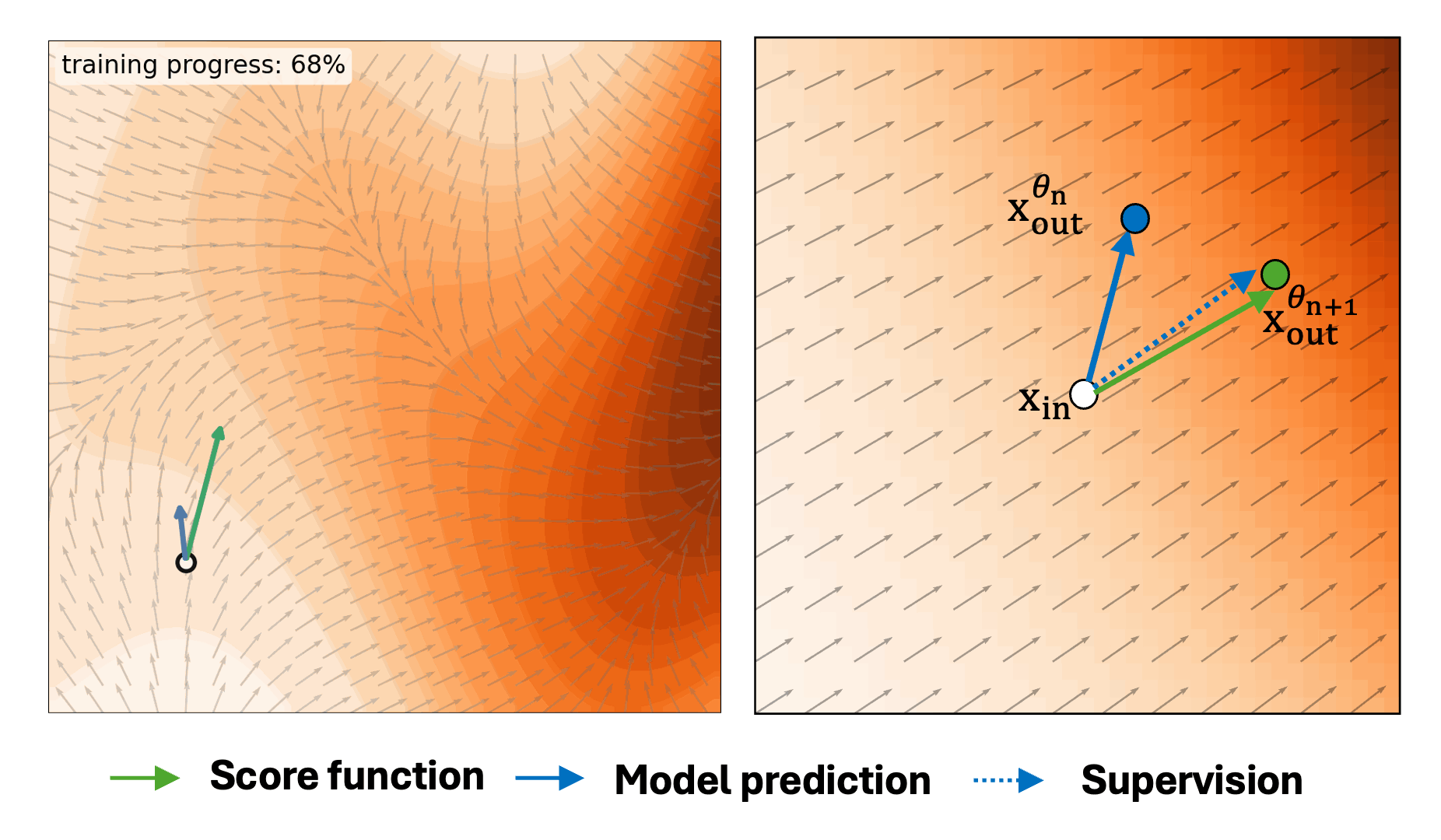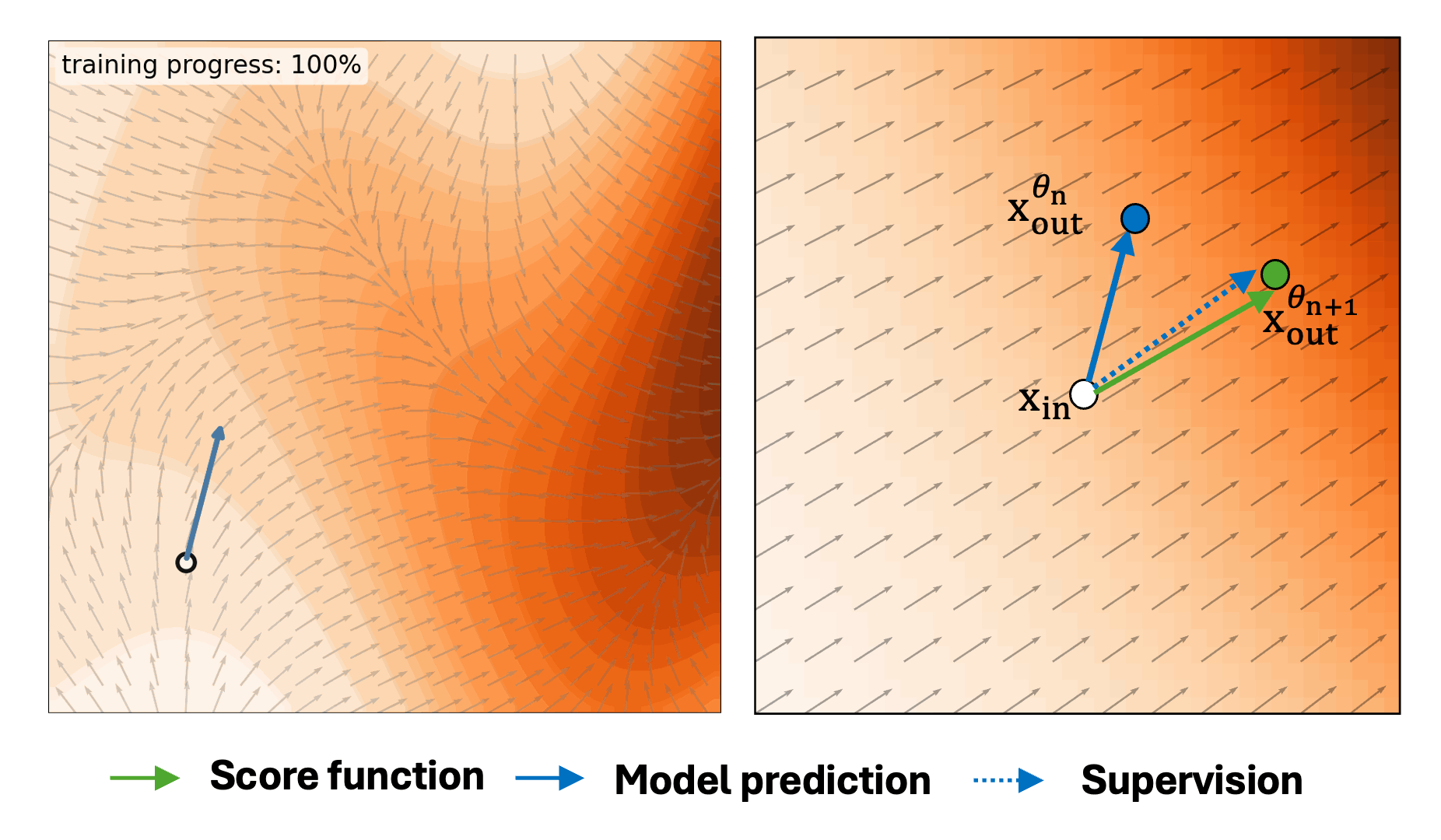
Self-Evaluation Unlocks Any-Step Text-to-Image Generation
Xin Yu, Xiaojuan Qi†, Zhengqi Li, Kai Zhang, Richard Zhang, Zhe Lin, Eli Shechtman, Tianyu Wang†, Yotam Nitzan†

LightMover: Towards Precise and Efficient Control for Light Movement
Gengze Zhou, Tianyu Wang, Soo Ye Kim, Zhixin Shu, Xin Yu, Yannick Hold-Geoffroy, Sumit Chaturvedi, Qi Wu, Zhe Lin, Scott Cohen
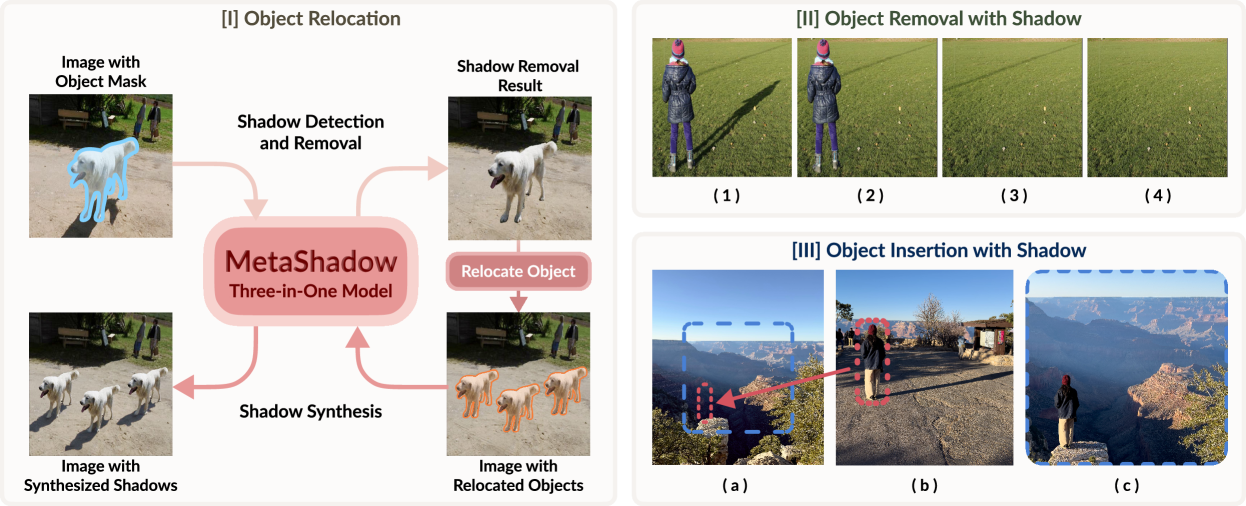
MetaShadow: Object-Centered Shadow Detection, Removal, and Synthesis
Tianyu Wang, Jianming Zhang, Haitian Zheng, Zhihong Ding, Scott Cohen, Zhe Lin, Wei Xiong, Chi-Wing Fu, Luis Figueroa†, Soo Ye Kim†

Generative Video Propagation
Shaoteng Liu, Tianyu Wang, Jui-Hsien Wang, Qing Liu, Zhifei Zhang, Joon-Young Lee, Yijun Li, Bei Yu, Zhe Lin, Soo Ye Kim†, Jiaya Jia†

ObjectMover: Generative Object Movement with Video Prior
Xin Yu, Tianyu Wang, Soo Ye Kim, Paul Guerrero, Xi Chen, Qing Liu, Zhe Lin, Xiaojuan Qi†
RetouchIQ: MLLM Agents for Instruction-Based Image Retouching with Generalist Reward
Qiucheng Wu, Jing Shi, Simon Jenni, Kushal Kafle, Tianyu Wang, Shiyu Chang, Handong Zhao
OmniVCus: Feedforward Subject-driven Video Customization with Multimodal Control Conditions
Yuanhao Cai, He Zhang, Xi Chen, Jinbo Xing, Yiwei Hu, Yuqian Zhou, Kai Zhang, Zhifei Zhang, Soo Ye Kim, Tianyu Wang, Yulun Zhang, Xiaokang Yang, Zhe Lin, Alan Yuille
Unveiling Deep Shadows: A Survey and Benchmark on Image and Video Shadow Detection, Removal, and Generation in the Deep Learning Era
Xiaowei Hu, Zhenghao Xing, Tianyu Wang, Chi-Wing Fu, Pheng-Ann Heng
Video Instance Shadow Detection Under the Sun and Sky
Zhenghao Xing, Tianyu Wang, Xiaowei Hu, Haoran Wu, Chi-Wing Fu, Pheng-Ann Heng
Learning Weather-General and Weather-Specific Features for Image Restoration Under Multiple Adverse Weather Conditions
Yi Zhu, Tianyu Wang, Xueyang Fu◯, Xin Yang, Xuejin Guo, Jiabin Dai, Yu Qiao, Xiaowei Hu◯
H2ONet: Hand-Occlusion-and-Orientation-aware Network for Real-time 3D Hand Mesh Reconstruction
Hao Xu, Tianyu Wang, Xiao Tang, Chi-Wing Fu
SILT: Shadow-aware Iterative Label Tuning for Learning to Detect Shadows from Noisy Labels
Han Yang, Tianyu Wang, Xiaowei Hu†, Chi-Wing Fu
Instance Shadow Detection with a Single-Stage Detector
Tianyu Wang, Xiaowei Hu, Pheng-Ann Heng, Chi-Wing Fu
Sparse2Dense: Learning to Densify 3D Features for 3D Object Detection
Tianyu Wang, Xiaowei Hu, Zhengzhe Liu, Chi-Wing Fu
Single-Stage Instance Shadow Detection With Bidirectional Relation Learning
Tianyu Wang, Xiaowei Hu†, Chi-Wing Fu, Pheng-Ann Heng
Revisiting Shadow Detection: A New Benchmark Dataset for Complex World
Xiaowei Hu, Tianyu Wang, Chi-Wing Fu, Yitong Jiang, Qiong Wang, Pheng-Ann Heng
Instance Shadow Detection
Tianyu Wang, Xiaowei Hu, Qiong Wang, Pheng-Ann Heng, Chi-Wing Fu
Single-Image Real-Time Rain Removal Based on Depth-Guided Non-Local Features
Xiaowei Hu, Lei Zhu, Tianyu Wang, Chi-Wing Fu, Pheng-Ann Heng
SAC-Net: Spatial Attenuation Context for Salient Object Detection
Xiaowei Hu, Chi-Wing Fu, Lei Zhu, Tianyu Wang, Pheng-Ann Heng
Spatial Attentive Single-Image Deraining with a High Quality Real Rain Dataset
Tianyu Wang, Xin Yang, Ke Xu, Shaozhe Chen, Qiang Zhang, Rynson W.H. Lau†
Towards Accurate Alignment in Real-time 3D Hand-Mesh Reconstruction
Xiao Tang, Tianyu Wang, Chi-Wing Fu
Film Photography
 01▲
01▲ 02▲
02▲ 03▲
03▲ 04▲
04▲ 05▲
05▲ 06▲
06▲ 07▲
07▲ 08▲
08▲ 09▲
09▲ 10▲
10▲ 11▲
11▲ 12▲
12▲ 13▲
13▲ 14▲
14▲ 15▲
15▲ 16▲
16▲ 17▲
17▲ 18▲
18▲ 19▲
19▲ 20▲
20▲ 21▲
21▲ 22▲
22▲ 23▲
23▲ 24▲
24▲ 25▲
25▲ 26▲
26▲ 27▲
27▲ 28▲
28▲ 29▲
29▲ 30▲
30▲ 31▲
31▲ 32▲
32▲ 33▲
33▲ 34▲
34▲ 35▲
35▲ 36▲
36▲ 37▲
37▲ 38▲
38▲ 39▲
39▲ 40▲
40▲ 41▲
41▲ 42▲
42▲ 43▲
43▲ 44▲
44▲ 45▲
45▲ 46▲
46▲ 47▲
47▲ 48▲
48▲ 49▲
49▲ 50▲
50▲ 51▲
51▲ 52▲
52▲ 53▲
53▲ 54▲
54▲ 55▲
55▲ 56▲
56▲ 57▲
57▲ 58▲
58▲ 59▲
59▲ 60▲
60▲ 61▲
61▲ 62▲
62▲ 63▲
63▲ 64▲
64▲ 65▲
65▲ 66▲
66▲ 67▲
67▲ 68▲
68▲ 69▲
69▲ 70▲
70▲ 71▲
71▲ 72▲
72▲ 73▲
73▲ 74▲
74▲ 75▲
75▲ 76▲
76▲ 77▲
77▲ 78▲
78▲ 79▲
79▲ 80▲
80▲ 81▲
81▲ 82▲
82▲ 83▲
83▲ 84▲
84▲ 85▲
85▲ 86▲
86▲ 87▲
87▲ 88▲
88▲ 89▲
89▲ 90▲
90▲ 91▲
91▲ 92▲
92▲ 93▲
93▲ 94▲
94▲ 95▲
95▲ 96▲
96▲ 97▲
97▲ 98▲
98▲ 99▲
99▲ 100▲
100▲ 101▲
101▲ 102▲
102▲ 103▲
103▲ 104▲
104▲ 105▲
105▲ 106▲
106▲ 107▲
107▲ 108▲
108▲ 109▲
109▲ 110▲
110▲ 111▲
111▲ 112▲
112▲ 113▲
113▲ 114▲
114▲ 115▲
115▲ 116▲
116▲ 117▲
117▲ 118▲
118▲ 119▲
119▲ 120▲
120▲ 121▲
121▲ 122▲
122▲ 123▲
123▲ 124▲
124▲ 125▲
125▲ 126▲
126▲ 127▲
127▲ 128▲
128▲ 129▲
129▲ 130▲
130▲ 131▲
131▲ 132▲
132▲ 133▲
133▲ 134▲
134▲ 135▲
135▲ 136▲
136▲ 137▲
137▲ 138▲
138▲ 139▲
139▲ 140▲
140▲ 141▲
141▲ 142▲
142▲ 143▲
143▲ 144▲
144▲ 145▲
145▲ 146▲
146▲ 147▲
147▲ 148▲
148▲ 149▲
149▲ 150▲
150▲ 151▲
151▲ 152▲
152▲ 153▲
153▲ 154▲
154▲ 155▲
155▲ 156▲
156▲ 157▲
157▲ 158▲
158▲ 159▲
159▲ 160▲
160▲ 161▲
161▲ 162▲
162▲ 163▲
163▲ 164▲
164▲ 165▲
165▲ 166▲
166▲ 167▲
167▲ 168▲
168▲